HDFS Client - Don't Fear the Command Line!
(continued from part 1, Distributed File Systems - Scaling)
(continued from part 2, Distributed File Systems - Recovery Process)
First things first, setting up HDFS CLI
Client in Hadoop refers to the Interface used to communicate with the Hadoop Filesystem.
The basic filesystem client hdfs dfs is used to connect to a Hadoop Filesystem and perform basic file related tasks. It uses the ClientProtocol to communicate with a NameNode daemon, and connects directly to DataNodes to read/write block data.
Before we get into using the HDFS Client, I’m going to assume you’re comfortable using the Unix command line interface (or CLI, for short).
To follow along, it’d be a good idea to install a Hadoop sandbox in a virtual machine, as most of us probably don’t have a personal Hadoop cluster to toy around with.
Stuff we’ll cover on HDFS client
-
Useful commands to get information from the Namenode and how to change meta information.
-
How to read and write data with the help of HDFS client.
-
How to transfer files between local and distributed storage.
-
How to change replication factor, update permissions to access data, and get a general report about files and blocks in HDFS.
Useful Help Commands
If you ever need help with the HDFS client API, use the following commands:
$
hdfs means you’re working with the hdfs client.
dfs means you’re working with the distributed file system API.
Using HDFS Client to communicate with the Namenode
Let’s do a read-only request to a name node.
drwxrwxrwx - mkwon supergroup 0 2017-11-28 21:41 /data/wiki/en_articles_part
-rwxrwxrwx 1 mkwon supergroup 73.3 M 2017-11-28 21:41 /data/wiki/en_articles_part/articles-part-ls let’s you see the directory content or the file information
-R gives you recursive output
-h shows file sizes in human readable format
Note: these file sizes don’t include replicas. To get the file sizes of space used by all replicas, use -du.
73.3 M /data/wikiNow let’s modify the structure of our file system by creating a directory called ‘deep’.
$
drwxr-xr-x - mkwon supergroup 0 2018-02-06 03:12 deep/nested
drwxr-xr-x - mkwon supergroup 0 2018-02-06 03:12 deep/nested/path-p If you try to create a deep nested folder, then you will get an error back
if parent folder doesn’t exist. To create parent folders automatically, use -p.
Alright let’s remove the ‘deep’ folder. Remember to use -r to delete folders recursively.
Deleted deepIn addition to folders, you can create empty files with touchz utility.
$
Found 2 items
-rw-r--r-- 1 mkwon supergroup 239 2017-11-28 21:41 README.md
-rw-r--r-- 1 mkwon supergroup 0 2018-02-06 04:33 file.txtThere’s a difference between using touch in the local file system and touchz in the distributed file system.
With touch, you use it to update file meta information (ie access and modification type).
With touchz, you create a file of zero length. That’s where the z comes from.
After creating ‘file.txt’, let’s try and move it to another location with a different name.
$
Found 2 items
-rw-r--r-- 1 mkwon supergroup 239 2017-11-28 21:41 README.md
-rw-r--r-- 1 mkwon supergroup 0 2018-02-06 16:55 another_file.txtmv can be used the same way as it is used in the local file system to manipulate files and folders.
Using HDFS Client to communicate with Data Nodes
So up until now, we’ve been communicating with the namenode.
Let’s move on and discover how to communicate with data nodes.
Use put to transfer a file from the local file system into HDFS.
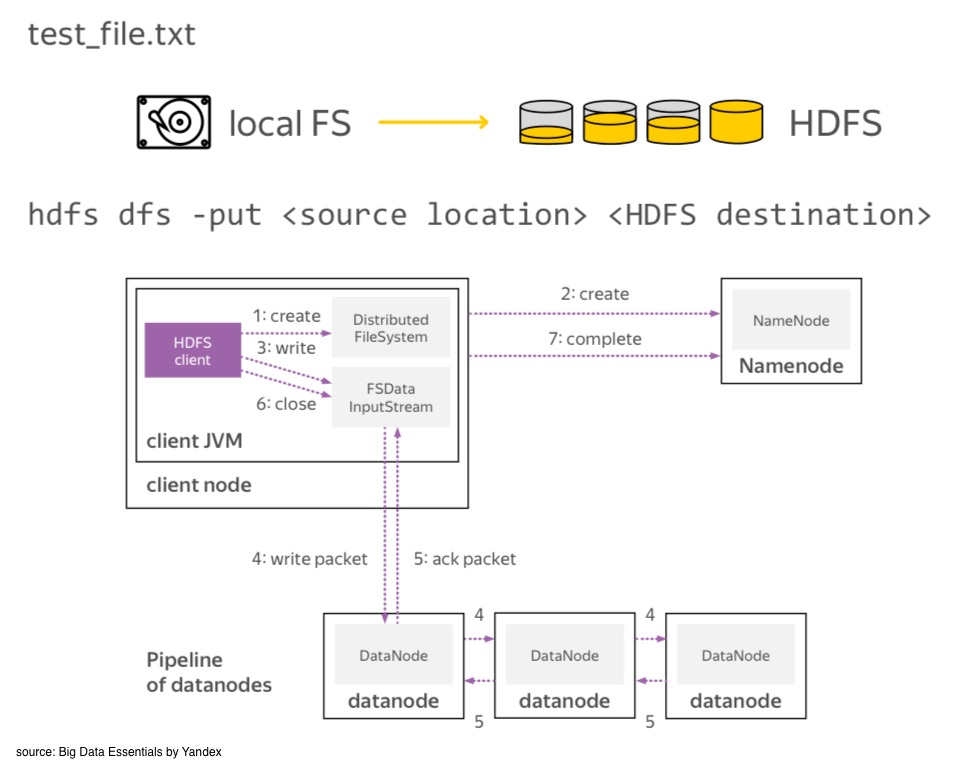
How do we read the content of a remote file?
In the local file system, we use cat, head, and tail to bring the content of a file to a screen.
In HDFS you can use a cat to bring the whole file to a screen.
test content #1
test content #2
test content #3
test content #4To see only the first lines of the file, use piping as there is no head utility in HDFS.
To see the end of the file you can use tail utility. Note that the behavior of
a local tail utility and the distributed tail utility is different. Local file system commands
are focused on text files. In a distributed file system, we work with binary data. So, the HDFS tail command brings out onto the
screen the last one kilobyte of a file.
test content #12
test content #13
test content #14
test content #15test content #1
test content #2
...
test content #15As with moving files from the local file system to HDFS, we can also download files from
HDFS to the local file system by using get.
$
$
-rw-r--r-- 1 mkwon mkwon 246 Apr 5 13:28 hdfs_test_file_copy.txt
-rw-r--r-- 1 mkwon mkwon 246 Apr 5 13:28 hdfs_test_file.txtWith the -getmerge utility, all of this data can be merged into one local file.
$
-rw-r--r-- 1 mkwon mkwon 492 Apr 5 13:32 hdfs_merged.txt
-rw-r--r-- 1 mkwon mkwon 246 Apr 5 13:28 hdfs_test_file_copy.txt
-rw-r--r-- 1 mkwon mkwon 246 Apr 5 13:28 hdfs_test_file.txtAdvanced Commands
So that covers the basic name node and data node APIs. The following are some more advanced commands.
chown, which stands for ‘change ownership’ can be used to configure access permissions.
groups is useful to get information about your HDFS ID
setrep provides API to decrease and increase replication factor
Replication 1 set: hdfs_test_file.txt
Waiting for hdfs_test_ le.txt ...
WARNING: the waiting time may be long for DECREASING the number of
replications...done
real 0m13.148s
user 0m4.232s
sys 0m0.156shdfs fsck, which stands for ‘file system checking utility’, can be used to request name node to provide you with the information
about file blocks and the allocations
Connecting to namenode via http://virtual-master.atp- vt.org:50070
FSCK started by mkwon (auth:SIMPLE) from /138.201.91.190 for path /data/wiki/en_articles
at Wed Apr 05 14:01:15 CEST 2017
/data/wiki/en_articles <dir>
/data/wiki/en_articles/articles 12328051927 bytes, 92 block(s): OKsys 0m0.148sConnecting to namenode via http://virtual-master.atp- vt.org:50070
FSCK started by mkwon (auth:SIMPLE) from /138.201.91.190 for path /data/wiki/en_articles
at Wed Apr 05 14:01:48 CEST 2017
/data/wiki/en_articles <dir>
/data/wiki/en_articles/articles 12328051927 bytes, 92 block(s): OK
0. BP-858288134-138.201.91.191-1481279621434:blk_1073808471_67650 len=134217728
Live_repl=3
1. BP-858288134-138.201.91.191-1481279621434:blk_1073808472_67651 len=134217728
Live_repl=3
2. BP-858288134-138.201.91.191-1481279621434:blk_1073808473_67652 len=134217728
Live_repl=3 ...Connecting to namenode via http://virtual-master.atp- vt.org:50070
FSCK started by mkwon (auth:SIMPLE) from /138.201.91.190 for path /data/wiki/en_articles
at Wed Apr 05 14:01:56 CEST 2017
/data/wiki/en_articles <dir>Connecting to namenode via http://virtual-master.atp- vt.org:50070
FSCK started by mkwon (auth:SIMPLE) from /138.201.91.190 at Wed Apr 05 14:17:54 CEST 2017
Block Id: blk_1073808569
Block belongs to: /data/wiki/en_articles/articles
No. of Expected Replica: 3
No. of live Replica: 3
No. of excess Replica: 0
No. of stale Replica: 0
No. of decommission Replica: 0
No. of corrupted Replica: 0
Block replica on datanode/rack:
virtual-node2.atp- vt.org/default is HEALTHY
Block replica on datanode/rack:
virtual-node3.atp- vt.org/default is HEALTHY
Block replica on datanode/rack:
virtual-node1.atp- vt.org/default is HEALTHYfind is used to search by pattern recursively in the folder
/data/wiki/en_articles_part
/data/wiki/en_articles_part/articles-partSummary
Here, we’ve covered how to request meta-information from the name node and change its structure. We also learned how to read and write data to and from data nodes in HDFS. And we also covered how to change the replication factor of files and get detailed info about the data in HDFS.
Sources:
Dral, Alexey A. 2014. Scaling Distributed File System. Big Data Essentials: HDFS, MapReduce and Spark RDD by Yandex. https://www.coursera.org/learn/big-data-essentials