Distributed File Systems - Recovery Process
(continued from part 1, Distributed File Systems - Scaling)
Block and Replica States
To understand the recovery process of HDFS, let’s first introduce two concepts:
1) Replica: A physical data storage on a data node. Usually, there are several replicas with the same content on different data nodes.
2) Block: This is meta-info storage on a name node that provides information about replicas’ locations and their states.

Both replica and block have their own states. First, let’s take a look at the data node replica states.
Replica States and Transitions

Finalized Replica
When a replica is in a finalized state, that means its content is frozen. ‘Frozen’ means that the meta-info for this block is aligned with its corresponding replicas’ states and data. This means you can safely read data from any data node and get the same exact content, preserving read consistency. Each block of data has a version number called Generation Stamp (GS). Finalized replicas are guaranteed to all have the same GS number.
Replica Being Written to (RBW)
In this state, the last block of a file is opened or reopened for appending. Bytes that are acknowledged by the downstream data nodes in a pipeline are visible for a reader of this replica. Additionally, the data-node and name node meta-info may not match during this state. In the case of failure, the data node will try to preserve as many bytes as possible with the goal of data durability.
Replica Waiting to be Recovered (RWR)
In short, this is the state of all RBW replicas after data node failure and recovery. RWR replicas will not be in any data node pipeline and therefore will not receive any new data packets. So they either become outdated and should be discarded, or they will participate in a special recovery process called a lease recovery if the client also dies.
Replica Under Recovery (RUR)
If the HDFS client lease expires, the replica transitions to RUR state. Lease expiration usually happens during the client’s site failure.
Temporary
As data grows and different nodes are added/removed from the cluster, data can become
unevenly distributed over the cluster nodes.
 A Hadoop administrator can spawn a rebalancing process or a data engineer can increase the replication factor of data for durability.
In these cases, newly generated replicas will be in a state called temporary.
It’s pretty much the same state as RBW, except the data is not visible to the user unless finalized.
In the case of failure, the whole data chunk is removed without any intermediate recovery state.
A Hadoop administrator can spawn a rebalancing process or a data engineer can increase the replication factor of data for durability.
In these cases, newly generated replicas will be in a state called temporary.
It’s pretty much the same state as RBW, except the data is not visible to the user unless finalized.
In the case of failure, the whole data chunk is removed without any intermediate recovery state.
Now, let’s take a look at the name node block states and transitions.
Block States and Transitions
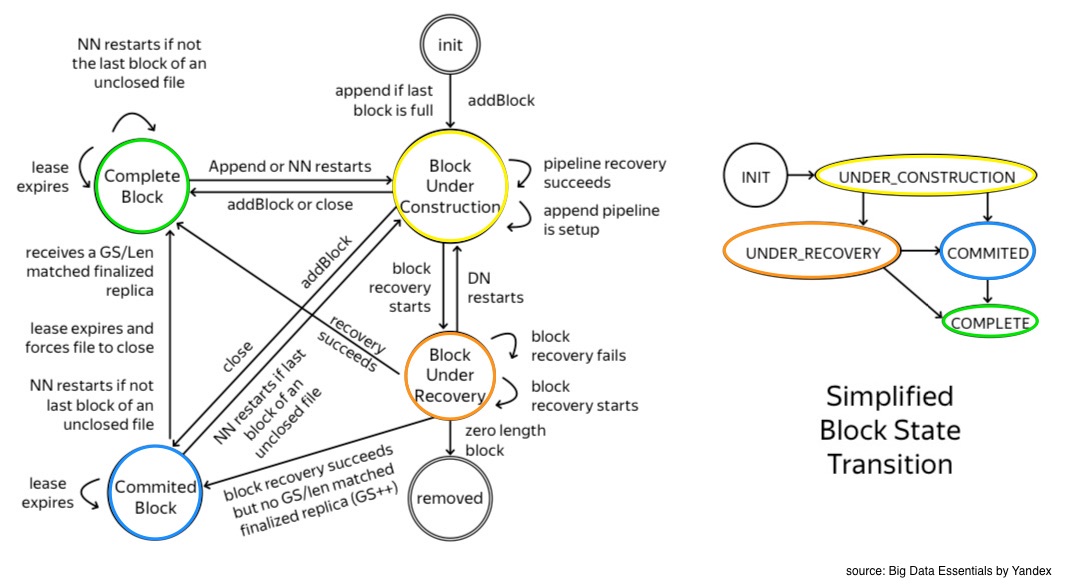
Block Under Construction
As soon as a user opens a file for writing, the name node creates the corresonding block in the under_construction state.
It is always the last block of a file and its length and GS stamp are mutable.
The name node block keeps track of the data pipeline and keeps a watchful eye over all RBW and RWR replicas.

Block Under Recovery
Replicas transition from RWR to RUR state when the client dies or when a client’s lease expires. Consequently, the corresponding block transitions from under_construction to the under_recovery state.

Committed
The under_construction block transitions to a committed state when a client successfully requests tge name node to close a file or to create a new consecutive block of data.
‘Committed’ that there are already some finalized replicas but not all are finalized. For this reason in order to serve a read request, the committed block needs to keep track of RBW replicas, until all the replicas are transitioned to the finalized state and HDFS client will be able to close the file.

Complete
Finally in the complete state, all the replicas are in the finalized state and therefore are identical and have same GS stamps. The file can be closed only when all the blocks of a file are in ‘complete’ state.

Having covered the states and transtions, let’s go into recovery procedures.
Recovery Procedures
There are several types of recovery procedures:
- Block Recovery
- Replica Recovery
- Lease Recovery
- Pipeline Recovery
Block Recovery
During the block recovery process, the namenode has to ensure that all of the corresponding
replicas of a block will transition to a common state, logically and physically,
mean that all the corresponding replicas should have the same content.
The NameNode choses a primary datanode (PD) which should
contain a replica for the target block. PD requests a new GS, info, and location of other replicas from the NameNode.
PD then contacts each relevant datanode to participate in the replica recovery process.

Replica Recovery
Replica recovery process include aborting active clients writing to a replica, aborting the previous replica or
block recovery process, and participating in final replica size agreement process.
During this phase, all the necessary info and data is propagated through the pipeline.

Lastly, PD notifies the NameNode of its success or failure. In case of failure, NameNode can retry block recovery.
Lease Recovery
The Block Recovery Process can only happen as a part of a Lease Recovery Process
 The Lease Manager manages all the leases at the NameNode where the HDFS clients request a lease every time they want to write to a file.
The Lease Manager maintains soft and hard time limits where if the current lease holder doesn’t renew its lease during the soft limit, another client will take over the lease.
If the hard limit is reached, the lease recovery process will begin.
The Lease Manager manages all the leases at the NameNode where the HDFS clients request a lease every time they want to write to a file.
The Lease Manager maintains soft and hard time limits where if the current lease holder doesn’t renew its lease during the soft limit, another client will take over the lease.
If the hard limit is reached, the lease recovery process will begin.
Throughout this process, there are a couple important of guarantees:
-
Concurrency control - event if the client is alive it won’t be able to write data to a file.
-
Consistency - All replicas should draw back to a consistent state to have the same data and GS.
Pipeline Recovery
When you write to an HDFS file, HDFS client writes data block by block. Each block is constructed through a write pipeline and each block breaks down into pieces called packets. These packets are propagated to the datanodes through the pipeline.

There are three stages to the pipeline recovery process:
-
pipeline setup: The client sends a setup message down through the pipeline. Each datanode opens a replica for writing and sends ack message back upstream the pipeline.
-
data streaming: In this part, data is buffered on the client’s site to form a packet, then propagated through the data pipeline. Next packet can be sent even before the acknowledgement of the previous packet is received.
-
close: This is used to finalize replicas, and shut down the pipeline
Summary
-
We talked about block and replica states and transitions.
-
We also covered the write pipeline stages and the four different recovery processes.
Now that the theory stuff is out of the way, it’s time to get our hands dirty. Next post, we’ll stretch our fingers and get familiar with writing commands in the HDFS Client.
(continue to part 3, Using HDFS Client - Don’t Fear the Command Line!)
Sources:
Dral, Alexey A. 2014. Scaling Distributed File System. Big Data Essentials: HDFS, MapReduce and Spark RDD by Yandex. https://www.coursera.org/learn/big-data-essentials